Big M’s in integer programming formulations have been a topic of discussion on Twitter and the blogosphere in the past week. For example, see Marc-Andre Carle‘s posts (primal and dual) and followup tweets and also some older posts from Paul Rubin and Bob Fourer.
My initial reaction was don’t let the software handle it. If possible, try to reformulate the problem.
In this post, I explain myself and give supporting computational experiments.
Example: The uncapacitated facility location problem
Consider the uncapacitated facility location (UFL) problem. The task is to open a subset of 

The parameters for this problem include the cost 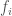



1. The disaggregated formulation
One natural formulation is as follows, where 
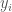
The objective is to minimize the total cost:

Each customer’s demand should be fulfilled:

If a facility is closed, then it can fulfill none of a customer’s demand:

Finally, the 

2. The big-M formulation
In the big-M formulation, everything is the same, except that the 

To keep the formulation as strong as possible, the value used for M should be as small as possible. In this case, we should set 
Which formulation is “better”?
Depending on who you ask, either of these formulations could be better. Many textbooks on integer programming prefer the first, since its LP relaxation is much stronger, meaning that the number of branch-and-bound nodes that will be explored is fewer. Results for 5 different benchmark instances with 
| LP 1 objective | LP 2 objective | |
| 123unifS | 67,441 | 12,271 |
| 623unifS | 70,006 | 12,674 |
| 1823unifS | 69,649 | 12,066 |
| 2623unifS | 68,776 | 11,958 |
| 3023unifS | 71,639 | 12,170 |
On the other hand, the big-M formulation has only 

When the aggregated formulation is given to state-of-the-art solvers, they are able to detect and generate disaggregated constraints on the fly, whenever these constraints are violated by the current feasible solution. So, in fact, it is preferable to use the aggregated formulation because the size of the linear relaxation is much smaller and faster to solve.
However, MIP solvers rely on sparse matrix representation, meaning that the number of nonzeros in the formulation is more indicative of its size than the quantity obtained by multiplying the number of variables by the number of constraints. Indeed, the number of nonzeros to impose the
So, I was not exactly convinced that the time to solve the LP relaxations would be much different and decided to run some experiments. Here are the times (in seconds) to solve the LP relaxations for the same 5 benchmark instances in Gurobi 7.0.2.
| Solve time for LP 1 | Solve time for LP 2 | |
| 123unifS | 0.115 | 0.022 |
| 623unifS | 0.125 | 0.023 |
| 1823unifS | 0.107 | 0.022 |
| 2623unifS | 0.128 | 0.022 |
| 3023unifS | 0.150 | 0.024 |
While the LP times are indeed longer for the disaggregated formulation, it is only by a factor of 5 or 6, even though the number of constraints has increased by a factor of 50!
However, what we are actually interested in is the time to solve IP. By this measure, the disaggregated formulation wins though both times are reasonable for these sized instances. Experiments for larger instances are in the appendix.
| Solve time for IP 1 | Solve time for IP 2 | |
| 123unifS | 3.496 | 8.151 |
| 623unifS | 1.607 | 7.176 |
| 1823unifS | 1.528 | 4.468 |
| 2623unifS | 1.263 | 3.415 |
| 3023unifS | 4.932 | 14.153 |
Conclusion
I have only provided test results for 5 UFL instances, so I cannot make any general conclusions about the (dis)advantages of big M’s from this post. However, I can say that one should at least look for alternative formulations that do not rely on big M’s and then empirically compare them.
I leave with a rhetorical question. Where would the field of integer programming be if everyone concluded that the Miller-Tucker-Zemlin formulation for TSP was good enough (even though it has big M’s)? What if they said “just let the solver take care of it”?
Appendix
I constructed larger instances following the same procedures that were used when making the
The LP times are much like before.
| Solve time for LP 1 | Solve time for LP 2 | |
| n=100,m=150 | 0.437 | 0.057 |
| n=100,m=200 | 0.506 | 0.076 |
| n=150,m=100 | 0.422 | 0.070 |
| n=200,m=100 | 0.641 | 0.083 |
So are the IP times.
| Solve time for IP 1 | Solve time for IP 2 | |
| n=100,m=150 | 178.049 | 225.599 |
| n=100,m=200 | 420.491 | 501.478 |
| n=150,m=100 | 51.808 | 153.065 |
| n=200,m=100 | 110.433 | 143.192 |
Somewhat surprisingly, the IP time for formulation 2 decreased when increasing the number of facilities from 150 to 200. Probably the solver got lucky.
I have designated the
| binary |
continuous |
|
| Solve time for IP 1 | 25.577 | 7.405 |
| Solve time for IP 2 | 46.358 | 12.897 |

I agree with your conclusion that one should always look for alternative formulations (and actually always in integer programming) but it also always depends on the underlying algorithm used.
It would be interesting to know what the comparison would look like if you use a Benders algorithm (like the one in the latest CPLEX). I don’t know the answer, but it might be different.
At a conference workshop shortly after the introduction of indicator constraints in CPLEX, an IBM presenter (responding to a question, I think) said that if you knew a tight values for M, you would probably be better off using it than using indicators (and essentially relying on CPLEX to derive a value for M). I don’t know if that advice still holds, but I’m inclined to think so.
Pingback: Big M: good in practice, bad in theory, and ugly numerically! | Thiago Serra's website